Wanneer er sprake is van een tabel, zoals bij bijvoorbeeld een webshop met een lijst van artikelen, is het vaak een handige optie om delen gelijksoortige HTML code te herkennen. En hieruit de URL van de link te halen.
De opzet van HTML
HTML is de programmeertaal waarin een websitepagina vaak geschreven is. HTML is onderverdeeld in groepen. Elke groep begint met '<.....>', bv <HTML> aan het begin van de pagina of <A> aan het begin van een link. Vlak na het teken '<' staat het hoofdcommando. Maar dit kan nog gevolgd worden door een of meer extra gegevens. Deze extra gegevens worden altijd weergegeven als '.....=".......". Voorbeelden hiervan zijn 'name="btnSearch" of 'value="1". Zo kan een groep geopend worden met <INPUT type="checkbox" name"="chkYesOrNo" value="1">. Vertaald is dit een invoerveld van het type checkbox, die de naam chkYesOrNo heeft gekregen en de waarde 1 heeft. De waarde 1 bij een checkbox houdt in dat de checkbox is aangevinkt.
De groep eindigt meestal met </.....>. Hierin wordt alleen het hoofdcommando herhaald. Dus als de groep is begonnen met bijvoorbeeld <form id="456" name="Personal Data">, dan eindigt de groep met </form>
Binnen een groep kunnen weer nieuwe groepen opgenomen worden. Maar een groep mag nooit binnen groep A starten en daarna in groep B eindigen. Wat dus mag is:
<HTML>
<FORM>
<A></A>
</FORM>
<FORM>
<A></A>
<A></A>
</FORM>
</HTML>
Wat niet mag is:
<HTML>
<FORM>
<A>
</FORM>
<FORM>
</A>
</FORM>
</HTML>
In dit laatste geval begint de groep <A> in de eerste <FORM> groep en eindigt in de tweede <FORM> groep.
De groep eindigt meestal met </.....>. Hierin wordt alleen het hoofdcommando herhaald. Dus als de groep is begonnen met bijvoorbeeld <form id="456" name="Personal Data">, dan eindigt de groep met </form>
Binnen een groep kunnen weer nieuwe groepen opgenomen worden. Maar een groep mag nooit binnen groep A starten en daarna in groep B eindigen. Wat dus mag is:
<HTML>
<FORM>
<A></A>
</FORM>
<FORM>
<A></A>
<A></A>
</FORM>
</HTML>
Wat niet mag is:
<HTML>
<FORM>
<A>
</FORM>
<FORM>
</A>
</FORM>
</HTML>
In dit laatste geval begint de groep <A> in de eerste <FORM> groep en eindigt in de tweede <FORM> groep.
HTML code bekijken met Firefox of Chrome
Om te kijken welke HTML code je kan gebruiken voor je performancetest, is het handig om eerst de HTML code op te vragen in je browser.
- Open de pagina van je keuze in Firefox of Chrome
- Klik op F12
Er verschijnt nu een extra venster in je browser, waarin de HTML code te zien is.
- Ga in Firefox naar het tabblad Inspector of ga in Chrome naar het tabblad Elements
- Klik op de knop die lijkt op de hieronder staan de afbeelding

- Klik op de link in de pagina, die geschikt is voor je performance test
De link wordt nu gemarkeerd in de HTML code weergegeven. Je kan zien dat de tekst in de groep <A> gelijk is aan de tekst op de HTML pagina.

JMeter - HTML code bekijken
Ook in JMeter kan je de HTML code bekijken. Dit is vooral handig als je straks bepaalt hebt hoe je de juiste links uit de HTML gaat halen. Je kan dan via JMeter zelf controleren of je wijze van selecteren goed werkt.
- Maak een test aan met meerdere HTML pagina's
- Klik in het menu op Add > Listener > View Results Tree
Een Results Tree element wordt toegevoegd.
- Klik op Start (de groene pijl naar rechts in de knoppenbalk bovenin)
De startknop wordt nu inactief
- Wacht tot de startknop weer actief is
Wanneer de startknop weer actief is, is de test afgerond
Nu gebruiken we de Result Tree om de HTML code te bekijken.
- Klik in de tree op View Result Tree
- Klik in de Result Tree op HTTP request
- Open het tabblad Response data
In dit tabblad zie je de HTML code van de pagina staan.

- Klik op Start (de groene pijl naar rechts in de knoppenbalk bovenin)
De startknop wordt nu inactief - Wacht tot de startknop weer actief is
Wanneer de startknop weer actief is, is de test afgerond
Nu gebruiken we de Result Tree om de HTML code te bekijken.
- Klik in de tree op View Result Tree
- Klik in de Result Tree op HTTP request
- Open het tabblad Response data
In dit tabblad zie je de HTML code van de pagina staan.

JMeter - De URL selecteren
Wanneer je URL's uit een tabel wil halen, bijvoorbeeld uit een opsomming van artikelen, is de regular expression vaak een handige optie. Hiermee selecteer je een deel van de HTML. En je geeft ook aan welk deel als variabele gebruikt moet gaan worden.
Tekst selecteren met regular expression
Bij regular expressions geef je met behulp van tekst en tekens aan welke tekstdelen je in een bepaalde tekst wil selecteren. De meest simpele vorm is gewoon de tekst zelf. Wanneer je een woord invoert, bijvoorbeel "Trui", dan worden alle tekstdelen met het woord "Trui" gevonden.
Maar je kan het zoeken ook uitbreiden. Met het teken "." geef je aan dat elk willekeurig karakter goed is. De regular expression "Ja." matcht dus met "Jas", maar ook met "Ja?". Ook het teken + wordt vaak gebruikt. Hiermee geef je aan dat een teken oneindig herhaald mag worden om te matchen. "Ba+s" matcht daarom met "Bas", "Baas" en "Baaas".
Vaak wil je dat het matchen stopt, zodra de eerste match gevonden is. Vooral als je algemene tekens gebruikt als ".". Wanneer je deze bijvoorbeeld gebruikt in de regular expression "k.+p", wil je dat deze in de tekst "kip kop koop" de tekstdelen "kip", "kop" en "koop" aangeeft. Niet de tekst "kip kop" of andere varianten. Als je echter de regular expression goed begrijpt, zie je dat deze ook aan dit tekstdeel voldoet. Om nu te voorkomen dat deze optie ook gevonden wordt, zet je achter het "+" teken het "?". Deze zorgt ervoor dat de match vanaf een bepaald punt in de tekst stopt zodra de match is bereikt. Zodra dus het matchen vanaf de "k'"van "kip" de volledige tekst "kip" vindt, stopt het matchen vanaf deze "k". En wordt doorgegaan naar de volgende "k", namelijk die van "kop".
De regular expression bepalen
In de HTML tekst is, zeker in een tabel, vaak een uniek kenmerk te vinden voor een link. Een pagina bevat veel links. Om het programmeren eenvoudiger te maken, krijgen de links in een tabel vaak een apart kenmerk, bijvoorbeeld een eigen opmaakstijl, een eigen naam of ze worden als header weergegeven. Dit laatste is herkenbaar, omdat een <A> groep voorafgegaan wordt aan <H1>, <H2> of <H3>. Dit is puzzel, die je moet leren, door te proberen. Maar ik zal twee voorbeelden uitwerken.
Regular expression Voorbeeld 1
Op deze blog zelf staan op "www.agiletestenbijnee.nl" een aantal blogs onder elkaar. En elk van deze blogs heeft ook een link naar de werkelijke blogs. Deze titels worden allemaal in een groep <H3> weergegeven, wat inhoudt dat ze een vrij kleine header hebben.
<h3 class='post-title entry-title' itemprop='name'>
<a href='http://www.agiletestenbijnee.nl/2016/02/een-team-is-een-project-op-zich.html'>Een team is een project op zich</a>
</h3>
Als je andere links opzoekt, zie je dat de <h3> groep er altijd voor staat en altijd gelijk is. Vervolgens zie je in het "href" gegeven de URL die je wil gaan opvragen.
De tekst voor het openen van groep <h3> kan je, door de herhaling, letterlijk overnemen in de regular expression. Hierna volgt een enter, die je in een regular expression kan vervangen met '\n'. Je regular expression is tot nu toe
<h3 class='post-title entry-title' itemprop='name'>\n
Nu volgt de groep waarin de link staat. Hierin zijn twee delen variabel. De inhoud van de link bij het gegeven "href" en de tekst die als link wordt weergegeven. De tweede staat tussen het begin en einde van de groep <a> in.
Deze twee variabele delen vervang je door '(.+?)' . De '(....) geeft aan dat de tekst hierbinnen opgenomen moet gaan worden in een variabele. De tekst '.+?' selecteert vervolgens alle tekst tussen het teken ervoor en het teken erna. Hierdoor wordt dus de inhoud van de variabele bepaalt. De links wordt vervolgens dus :
<a href='(.+?)'>(.+?)</a>
Deze twee achter elkaar geplakt, geeft dan de volledige regular expression.
<h3 class='post-title entry-title' itemprop='name'>\n<a href='(.+?)'>(.+?)</a>
Regular expression Voorbeeld 2
Op de site van "www.wehkamp.nl" wordt ook regelmatig een lijst met artikelen getoond. Hier komt bijvoorbeeld deze code vandaan.
<a class="l-article-card" href="http://www.wehkamp.nl/damesmode/dames-truien-vesten/dames-truien-vesten/expresso-cyriel-vest/C21_1AB_1AB_637573/?MaatCode=0040&PI=0&PrI=80&Nrpp=96&Blocks=0&Ns=D&NavState=%2f_%2fN-1y6x&IsSeg=0&SelSegCode=&SelSegType=">Expresso Cyriel vest</a>
Wat je ziet is dat de groep <a> een speciaal gegeven heeft, namelijk de "class". Deze heeft een naam, die je veel doet denken aan een kenmerk specifiek voor het tonen van een artikel. Namelijk "l-article-card". Dit gegeven zie je ook terugkomen bij andere artikelen in de lijst en lijkt daarmee bruikbaar om links naar artikelen in de tabel te identificeren.
Ook in deze link zijn twee delen variabel; opnieuw de inhoud van de link bij het gegeven "href" en de tekst die als link wordt weergegeven. Dus als je deze vervangt, zoals hierboven beschreven, krijg je de volgende regular expression:
<a class="l-article-card" href="(.+?)">(.+?)</a>
JMeter - Regular expression testen
De result view biedt de mogelijkheid om een regular expression te testen.
Klik in de tree op View Result Tree
Klik in de Result Tree op HTTP request
Selecteer in de dropdown boven de resulttree de keuze "RegExp Tester"

Er verschijnt nu een tabblad RegExp Tester.
Maar je kan het zoeken ook uitbreiden. Met het teken "." geef je aan dat elk willekeurig karakter goed is. De regular expression "Ja." matcht dus met "Jas", maar ook met "Ja?". Ook het teken + wordt vaak gebruikt. Hiermee geef je aan dat een teken oneindig herhaald mag worden om te matchen. "Ba+s" matcht daarom met "Bas", "Baas" en "Baaas".
Vaak wil je dat het matchen stopt, zodra de eerste match gevonden is. Vooral als je algemene tekens gebruikt als ".". Wanneer je deze bijvoorbeeld gebruikt in de regular expression "k.+p", wil je dat deze in de tekst "kip kop koop" de tekstdelen "kip", "kop" en "koop" aangeeft. Niet de tekst "kip kop" of andere varianten. Als je echter de regular expression goed begrijpt, zie je dat deze ook aan dit tekstdeel voldoet. Om nu te voorkomen dat deze optie ook gevonden wordt, zet je achter het "+" teken het "?". Deze zorgt ervoor dat de match vanaf een bepaald punt in de tekst stopt zodra de match is bereikt. Zodra dus het matchen vanaf de "k'"van "kip" de volledige tekst "kip" vindt, stopt het matchen vanaf deze "k". En wordt doorgegaan naar de volgende "k", namelijk die van "kop".
De regular expression bepalen
In de HTML tekst is, zeker in een tabel, vaak een uniek kenmerk te vinden voor een link. Een pagina bevat veel links. Om het programmeren eenvoudiger te maken, krijgen de links in een tabel vaak een apart kenmerk, bijvoorbeeld een eigen opmaakstijl, een eigen naam of ze worden als header weergegeven. Dit laatste is herkenbaar, omdat een <A> groep voorafgegaan wordt aan <H1>, <H2> of <H3>. Dit is puzzel, die je moet leren, door te proberen. Maar ik zal twee voorbeelden uitwerken.
Regular expression Voorbeeld 1
Op deze blog zelf staan op "www.agiletestenbijnee.nl" een aantal blogs onder elkaar. En elk van deze blogs heeft ook een link naar de werkelijke blogs. Deze titels worden allemaal in een groep <H3> weergegeven, wat inhoudt dat ze een vrij kleine header hebben.
<h3 class='post-title entry-title' itemprop='name'>
<a href='http://www.agiletestenbijnee.nl/2016/02/een-team-is-een-project-op-zich.html'>Een team is een project op zich</a>
</h3>
Als je andere links opzoekt, zie je dat de <h3> groep er altijd voor staat en altijd gelijk is. Vervolgens zie je in het "href" gegeven de URL die je wil gaan opvragen.
De tekst voor het openen van groep <h3> kan je, door de herhaling, letterlijk overnemen in de regular expression. Hierna volgt een enter, die je in een regular expression kan vervangen met '\n'. Je regular expression is tot nu toe
<h3 class='post-title entry-title' itemprop='name'>\n
Nu volgt de groep waarin de link staat. Hierin zijn twee delen variabel. De inhoud van de link bij het gegeven "href" en de tekst die als link wordt weergegeven. De tweede staat tussen het begin en einde van de groep <a> in.
Deze twee variabele delen vervang je door '(.+?)' . De '(....) geeft aan dat de tekst hierbinnen opgenomen moet gaan worden in een variabele. De tekst '.+?' selecteert vervolgens alle tekst tussen het teken ervoor en het teken erna. Hierdoor wordt dus de inhoud van de variabele bepaalt. De links wordt vervolgens dus :
<a href='(.+?)'>(.+?)</a>
Deze twee achter elkaar geplakt, geeft dan de volledige regular expression.
<h3 class='post-title entry-title' itemprop='name'>\n<a href='(.+?)'>(.+?)</a>
Regular expression Voorbeeld 2
Op de site van "www.wehkamp.nl" wordt ook regelmatig een lijst met artikelen getoond. Hier komt bijvoorbeeld deze code vandaan.
<a class="l-article-card" href="http://www.wehkamp.nl/damesmode/dames-truien-vesten/dames-truien-vesten/expresso-cyriel-vest/C21_1AB_1AB_637573/?MaatCode=0040&PI=0&PrI=80&Nrpp=96&Blocks=0&Ns=D&NavState=%2f_%2fN-1y6x&IsSeg=0&SelSegCode=&SelSegType=">Expresso Cyriel vest</a>
Wat je ziet is dat de groep <a> een speciaal gegeven heeft, namelijk de "class". Deze heeft een naam, die je veel doet denken aan een kenmerk specifiek voor het tonen van een artikel. Namelijk "l-article-card". Dit gegeven zie je ook terugkomen bij andere artikelen in de lijst en lijkt daarmee bruikbaar om links naar artikelen in de tabel te identificeren.
Ook in deze link zijn twee delen variabel; opnieuw de inhoud van de link bij het gegeven "href" en de tekst die als link wordt weergegeven. Dus als je deze vervangt, zoals hierboven beschreven, krijg je de volgende regular expression:
<a class="l-article-card" href="(.+?)">(.+?)</a>
JMeter - Regular expression testen
De result view biedt de mogelijkheid om een regular expression te testen.
- Voer de regular expression in in het veld Regular expression
- Klik op Test
Als je regular expression nu goed is, krijg je resultaten te zien.

JMeter - Interpreteren resultaat
Bovenaan staat het aantal gevonden matches. Elke match heeft een eigen unieke nummer. Dit unieke nummer is het eerste nummer wat tussen blokhaken staat achter het woord Match. Alles wat begint met Match[3] heeft dus betrekking op de derde gevonden match.
Hierna volgen de variabelen. Standaard wordt de gehele gevonden tekst geplaatst op plek 0. Deze plek wordt vervolgens tussen blokhaken achter de beschrijving van de match geplaatst. Match[5][0] bevat dus de volledige gevonden tekst van de vijfde gevonden match. Na de volledige tekst volgen de aangegeven variabelen. De eerste aangegeven variabele krijgt plek 1, de tweede plek 2, enz. In het geval van het Wehkamp voorbeeld zou Match[7][2] dus inhouden dat in deze variabele de gelinkte tekst staat (de tweede variabele in de regular expression) van het zevende gevonden artikel.
JMeter - JMeter test baseren op regular expression
Gegevens via regular expression inlezen
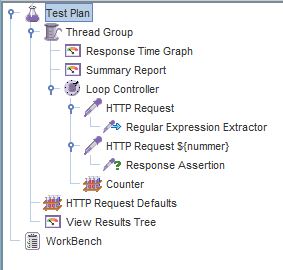
- Verwijder het element CSV Data Set config uit de tree
- Klik met de rechtermuisknop op HTTP Request
- Klik in het menu op Add > Post Processors > Regular Expression Extractor
Door dit element onder de HTTP Request te plaatsen, geef je aan dat de ingevoerde regular expression op deze HTML pagina moet worden toegepast.
- Klik in de tree op Regular Expression Extractor

- Voer bij Reference Name de waarde Link in
- Voer bij Regular Expression de door jou gekozen regular expression in
- Voer de template in op de volgende wijze:
Voer $1$ in voor de eerste variabele in de regular expression. Als er een tweede variabele is, voer dan hierachter de waarde $2$ in. Bij een derde, voeg dan nog de waarde $3$ toe.
- Voer bij Match No. de waarde 0 in
Hier geef je aan welke match opgehaald moet worden. Bij de waarde 3, wordt de derde match gebruikt. De waarde 0 zorgt ervoor dat er een willekeurige match wordt gekozen. Hier kiezen we voor, omdat er sprake is van een herhalende actie en we niet steeds dezelfde link willen opvragen.

- Klik in de tree op Response Assertion
- Selecteer in de tabel de bestaande controle
- Klik op Delete
De controle wordt verwijderd - Klik op Add
- Voer in de nieuwe regel in de tabel de waarde ${Link_g2}in

Dit gaat uit van het principe dat, zeker in tabellen, de tekst die gelinkt wordt, altijd terugkomt op de pagina waarnaar gelinkt wordt. Als dit niet het geval is, is het verstandig om de controle te verwijderen.
Nu is de test gebaseerd op URL's uit de website. Op deze wijze kom je steeds dichter bij een werkelijke gebruiker.
Geen opmerkingen:
Een reactie posten
Opmerking: Alleen leden van deze blog kunnen een reactie posten.